双侧检验的p值和单侧检验_参数检验


检验分为参数检验和非参数检验。参数检验假定数据可以由一个或多个参数定义的分布很好地描述,在大多数情况下是通过正态分布来描述的。对于给定的数据集,需要确定并解释该分布的最佳拟合参数和它们的置信区间。但是只有给定的数据集和被选择的分布近似的时候才能正常工作,否则就要用非参数检验就是因为它不依赖服从特定的分布。
所以在参数检验之前,需要做正态性检验。
一、正态性检验
因为在假设检验过程中有很多场景需要判断总体是否服从正态分布,所以要在实验前先判断总体的分布情况,判断总体是否是正态分布的方法有如下几种:
(1)概率图
QQ图 Q指的是quantile(分位数),将给定数据集的分位数和参考分布的分位数一起绘制
PP图 将guessing数据集的CDF和参考分布的CDF一起绘制
概率图 绘制了给定数据集的有序数值和参考分布的分位数
(2)常见分布
基于和给定分布比较最佳拟合的检验 常根据CDF来确定
基于样本的描述性统计学的检验 如偏度检验、峰度检验等
二、假设检验
假设检验是在统计学中非常重要的知识点,也是各大面试中的高频考点,而且在工作中最常用到的一个场景ABtest,也是高频点,接下来就捋一下那些年我们一起学过的假设检验...
假设检验的思想就是小概率事件,是先对未知总体参数进行一个假设,然后再用样本信息对这个假设是否成立进行验证。在工作场景中最常见的应用就是ABtest。假设检验就是首先对参数提出一个假设,然后用样本信息去检验这个假设是否成立。
(1)第一类错误和第二类错误
第一类错误是弃真错误alpha,也就是在原假设是真的前提下被拒绝的概率,在工作中也就是AB两种方案没有差别,但却认为两者有差别而导致错误上线的情况,又叫做显著性水平,是由人们根据检验的要求确定的,一般是0.05或者0.01,也就是当做出接受原假设的决定时,正确的概率是95%或者99%,是从我们能接受的精确度来出发的,根据边界来看是落入接受域还是拒绝域。在参数估计中,alpha表示风险值,是总体均值不包括在置信区间内的概率,其实就是原假设为真的时候落入拒绝域的概率,1-alpha是置信水平,其实也就是落入接受域的概率。置信区间包括总体均值=原假设为真落入接受域,置信区间不包括总体均值=原假设为真落入拒绝域,参数估计和假设检验都是利用样本对总体进行推断,只是推断的角度不同,实际上最终的结果是一致的。
P值是对第一类错误的更精确的度量,如果最开始就限定了第一类错误,那么只要落入拒绝域的都会拒绝,但并不知道拒绝的程度有多大,相当于第一类错误只是一个通用的风险,但是不同场景下其实风险是不同的,所以要利用P值来更精确地反映决策的风险度。P值的含义是当原假设为真时所得到的样本观察结果或者更极端结果出现的概率。如果P值很小,说明这种情况发生的概率很小,而如果发生了,根据小概率原理,那么有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。换句话说,也就是在原假设为真的前提下,仅仅因为运气而得到一个极端或者更极端的值的可能性,它是用来测量假设的证据。
它的优点是反映了观察到的实际数据(每次抽样计算得到的P值是不同的)与原假设之间不一致的概率值,而不只是一个边界值,提供了更多的信息。如果事先确定了显著性水平比如0.05,那么在双侧检验中如果P>0.025不能拒绝原假设,P<0.025拒绝原假设。
第二类错误是采伪错误beta,也就是在原假设为假的前提下被接受的概率,在工作中也就是AB两种方案确实有差异的前提下,能够被检测出来的概率,但是能够被检测出来也是需要一定的条件的,比如样本量等才会检测出来,这里不得不提一个概念:功效分析
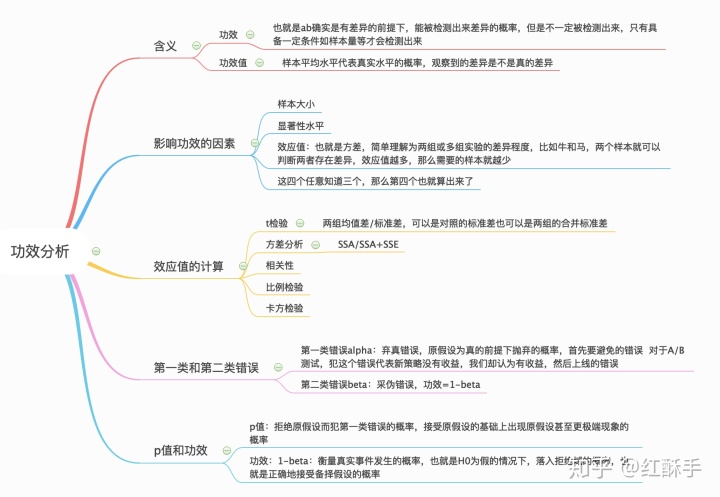
功效就是在备择假设为真的情况下,检验正确地拒绝了原假设的概率。
功效分析包括4个因素:
第一类错误的概率
第二类错误的概率
效应的大小,即所研究的功效相对样本的标准差的大小
样本大小
只有3个可被选择,第4个固定住了。
在假设检验中,我们会在控制犯第一类错误的前提下减少犯第二类错误的概率,在选择第一类错误的时候,是以H0为真的前提下进行的,也就是正常情况下事件结果应该和H0相差不远,如果发生了与H0不一致的、概率小于显著性水平的事件,则拒绝H0,否则不拒绝H0。这种反证法的保证了犯第一类错误的概率不超过alpha,但无法提供犯第二类错误的概率,可以采用功效分析的方式。
(2)假设检验的具体流程
假设检验的具体流程有:
首先提出原假设和备择假设
确定合适的检验统计量,通常要根据样本量的大小、总体标准差是已知还是未知,这些因素与参数估计确定统计量的标准相同
选择了合适的统计量,然后根据样本算其数值
根据计算结果,看是否落在拒绝域。以0.05为例,如果原假设为真,那么一次试验中统计量落在两侧拒绝域的概率只有0.05,这个概率很小,如果这个情况真的出现,那么我们有理由拒绝原假设。
检验分单侧和双侧,双侧有两个拒绝域两个临界值,即如果出现了>或者<的任意情况,就可以拒绝原假设;而单侧,就是当假设问题带有方向性,一些问题我们希望越大越好,比如灯泡的寿命等,另一些问题我们希望越小越好,比如废品率,这时候我们就要用单侧。
单侧的方向由原假设的方向来定,如果原假设是>=,那么是左侧检验,也就是希望值越大越好,关心的是数据的下界,拒绝域在左侧。
关于如何确定原假设和备择假设,通常原假设是我们原有的、传统的观点,希望验证的观点放在备择假设上,由于拒绝原假设需要落入拒绝域,那么原假设其实是具有优势的,由小概率原理,备择假设在一次实验中是不容易发生的,但一旦发生就有充足的理由拒绝原假设;对于左侧和右侧来说,如果是一个比较优质的情况,人们更愿意选择左侧检验,因为相信它是符合预期的,使得达到标准的产品只以很低的概率被拒绝;而对于一个比较不好的情况,人们更愿意相信它可能还是不好的,所以选择右侧检验,必须要充分好人们才能够相信它确实好
(3)检验统计量的确定
主要由两点来决定:
样本量
总体标准差是已知还是未知
也就是在大样本的情况下,无论总体是否是正态分布,无论总体标准差是否已知,都使用z统计量,因为在大样本下,根据中心极限定理,样本近似于正态分布,总体标准差未知的情况下可以用样本标准差s来代替;而如果是小样本的情况下,如果总体标准差已知且为正态分布那么就可以使用z统计量,如果总体标准差未知只能使用t统计量
三、拟合优度检验(一个分类变量)
(1)基本定义
根据总体的分布状况,计算出分类变量中各类别的期望频数,与分布的观察频数对比,判断期望频数和观察频数是否有显著差异,从而达到对分类变量分析的目的。可以对二项分布进行检验也可以对多项分布做检验。
(2)分析步骤
用到的检验统计量为卡方统计量:
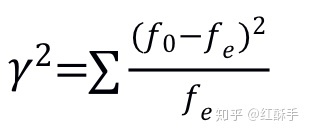
它可以用来测定分类变量之间的相关程度,f0表示观察值频数,f1表示期望值频数,随着自由度的增大而逐渐趋向正态分布,可以用来对分类数据进行拟合优度检验和独立性检验,其临界值的自由度是由分类变量的个数来决定的,是个数-1,最常见的是泰坦尼克的生存结果和男女是否有关系。
比如在做AB test中,A和B的短信文案不同导致最后的结果有差异,但是如果妄下结论认为确实A好于B或者B好于A是不合理的,这时可以借助拟合优度检验来辅助检测这种差异究竟是真正的差异还是由于样本的随机性导致的差异。
四、独立性检验(两个分类变量)
拟合优度检验是对一个分类变量的检验,而独立性检验是对两个分类变量的检验,也被称为列联表检验。列联表检验是由两个以上的变量进行交叉分类的频数分布表,独立性检验就是分析列联表中行变量和列变量是否独立,也就是如下的地区和原料质量是否存在依赖关系。

核心还是上面的计算规则,只不过期望的计算变成了如下的计算方式:
假设两个变量之间是相互独立的,那么第一个单元格的期望比例计算是:
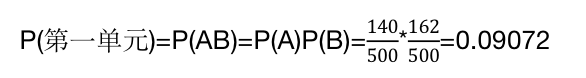
那么第一单元的期望值是0.09072*500=45.36
计算每个单元中频数的期望值为RT*CT/n,其中RT是单元所在行的合计,CT是所在列的合计,n为观察值的总数。同样要用到卡方检验。
五、方差分析(ANOVA)
(1)基本定义
名字是方差分析,其实主要是比较总体的均值,在判断均值是否有差异时要借助方差。
方差分析是检验多个总体的均值是否相等来判断分类型自变量对数值型因变量是否有影响。它的优点是可以增加分类的可靠性。如果要研究4个总体的均值那么要两两比较需要比较6次,如果每次犯第一类错误的概率都是0.05,那么随着实验次数的增多会增大犯错误的概率。一般来说,随着增加个体显著性检验的次数,偶然因素导致差别的可能性也会增大(并非均值真的存在差别),而方差分析就是同时考虑所有的样本,因此排除了错误累积的概率,从而避免拒绝一个真实的原假设。
其实方差分析是通过对数据误差来源的分析来判断不同总体的均值是否相等从而来分析自变量是否对因变量有显著影响。误差主要有两个来源:一是组内误差(SSE)二是组间误差(SSA)。组内误差就是由于随机因素造成的组内随机误差,组间误差就是不同水平之间的误差,这种误差可能是由于随机性导致的也可能是由于本身的系统性误差导致的,误差是用平方和来表示的。总的误差为SST,有SST=SSE+SSA,也就是说,如果不同水平之间没有差异,那么组间误差就应该近似等于组内误差,比值就会接近1,而如果本身存在差异那说明还存在系统误差,这样比值就会>1,比值越大说明水平之间的差异越大,这样说明自变量确实对因变量有影响。
基本假定:
每个总体应该服从正态分布
各个总体的方差必须相同
观测值是独立的
(2)分析步骤
方差分析中的误差可以拆解为两部分:SST=SSE+SSA
总平方和SST为全部观测值与总均值的误差平方和,组间平方和SSA为各组均值与总均值的误差平方和,组内平方和SSE为各组观测值与各组均值的误差平方和,用到的是F统计量。
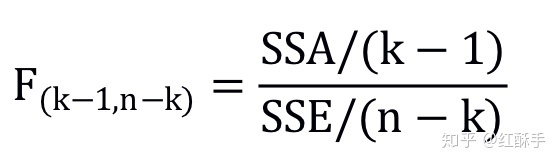
跟临界值比较,若计算出来的统计量的值>临界值,那么要拒绝原假设,也即不同水平之间有显著差异(差异越大值越大),否则就不拒绝原假设。
(3)其他
关系强度的测量
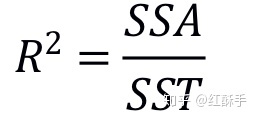
也就是看因变量有多少比例可以被自变量解释
多重比较
费希尔提出的最小显著性差异方法
————————————————
版权声明:本文为CSDN博主「云山雾村」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_28922227/article/details/112457829


| 文章 | 点赞 | 获赞 | 粉丝 | 关注 |
| 2430 | 433 | 181 | 147 | 44 |
- 2024.4.14
- 诊断实验的两大指标!灵敏度和特异性
- 最受欢迎的演讲的六大要素(内容层面,准备讲稿请参考此标准)
- 《写作需要打造的三大核心能力》笔记
- 毛姆:让人一看就幡然醒悟的10句名言
- 樊荣强:俞敏洪的人设会不会崩塌?
- 八个问题,让成年人更懂《千与千寻》
- 樊荣强:强迫自己换位思考
- HR人力资源的定义及含义
- 《元思维》深度解读:探索思考的本质与智慧
- 樊荣强:问题就是你感觉到某个东西的存在
- 当别人不相信你的时候,随便你说什么,都是多余的
- 休谟:理性的作用在于支持已作的决定,而不是作决定
- 樊荣强:为什么不要太在乎别人的看法?
- 樊荣强:董宇辉,让我来教你怎么做名人!
- 樊荣强:逢场作戏是我的人生态度
- 樊荣强:“名正言顺”这个成语,你知道它有几种含义?
- 樊荣强:写文章为什么那么难?把作文课设置为独立课程可以吗?
- 樊荣强:为什么一定要原谅伤害过你的人?
- 强迫性重复创伤?你知道么
- 领导常说的提炼是啥意思?文字如何做好加减法
- 梦回陪都17:探访宋子文公馆“怡园”
- 樊荣强:狗认为屎是香的还是臭的?
- 樊荣强:人生是一个妥协的过程
- 梦回陪都17:探访宋子文公馆“怡园”
- 3.17
- 有一天我会死的,这个世界上会没有我任何存在过的痕迹
- 樊荣强的《元写作》揭示了轻松写作的另一种可能,将无数觉得写作困难的人救出苦海
- 樊荣强的《魔力演讲法则》书籍简介
- 费正清:汉朝儒家思想的胜利

